Succumbed to temptation today and bought a laptop. I’ve been thinking about it for a while. In two more weeks, I’ll need to hand back in the one I’ve been using from work. This Macbook has stood me well through college and capture the flags, and I’ll be sad to see it go, particularly since it’ll take another week after that before my new one arrives. That said, 32GB of RAM, a 1 TB NVME drive, an NVIDIA GPU with 8GB, and an AMD Ryzen chip: gotta put this poor box to shame. I’m going to have to grow my chops in reverse engineering and cyber exploitation to match it!
Author: Tina
Solved a thing
You may have seen a few more geek notes on here of late. I’ve really enjoyed jumping into CTFs. My objective isn’t to win, but to find more ways to solve puzzles.
This weekend’s adventures were a little different, though. My company sponsors UMBC’s CyberDawgs team, and they’ve asked us to contribute challenges to their upcoming CTF. I tasked our IRAD team with coming up with a few and I wrote a couple, as well. So this weekend I spent some normalizing our submissions’ README files and doing a final test of the submissions.
One of the submissions was really giving me trouble. The IRAD team member who’d developed it had demonstrated it to us, but the solution instructions in the README just weren’t “clicking” to then be able to reproduce a solve, much less help anyone else understand how to solve. It’s customary in CTFs to have a Discord channel where mentors can offer assistance to those on the right track; given that I don’t want to be up all night myself providing that support, thought it best to provide a walkthrough for someone else..
Not only did I “crack” it (helped, of course, by the solution instructions in his README), but then I was able to provide a linked reproducible recipe using a tool called CyberChef that is really useful for a lot of CTF grunt work. I’m avoiding linking to the recipe or giving any more info on the challenge, of course, given that there’ll be hopefully lots of folks taking a crack at it in early May. I’m now more confident, though, that there may be some folks who solve it AND I better understand a particular kind of encryption approach.
CTF notes
Notes from this week’s CTF – geek notes for Tina. Should have collected notes on more challenges, but, eh…
Received a PCAP file that said it had secret coordinates in it. PCAP was completely USB traffic, specific URB_INTERRUPT
- https://wiki.osdev.org/USB_Human_Interface_Devices#USB_keyboard
- Isolated traffic for appropriate device, after examining device descriptor response to find keyboard
- Started mapping out the HID keys by hand, until a teammate suggested https://github.com/TeamRocketIst/ctf-usb-keyboard-parser
- Ultimately used tshark to extract the data, via
tshark -r ~/Downloads/file.pcap -Y 'usb.device_address == 2 and usb.data_len > 0 and !(usbhid.data == 00:00:00:00:00:00:00:00)' -T fields -e usbhid.data | sed 's/../:&/g' | sed 's/^://g' > keys.txt - (Note: the second se is because the recommended one ended up prefixing all the lines with : – second sed strips it off)
You know you’re a geek when…
I gave a talk in November to a local high school about computer science as a career field. Aha, I think – I’ve given this talk before – I’ll just brush up my well-prepared slide deck.
My slide deck has a graphic in it that looks something like the below. All credit to Daniel van der Ende and his work on the GitHub Data Challenge in 2014. It’s an interesting way to show the various combinatrics of languages that are used in projects today. It’s actually common nowadays that a project has multiple types of code in it. Often there’ll be the front-end (often JavaScript + HTML + CSS) with some sort of back-end. The point I wanted to convey in the original presentation was that software engineers often don’t just need to know one language. I then would riff lightly one which of the languages they could see in my slide I’d worked with in some form or fashion. (In the snippet you can see of the image, Perl, Scala, Go, JavaScript, Ruby, and Lua. I did just enough of CoffeeScript to not want to do it anymore…)
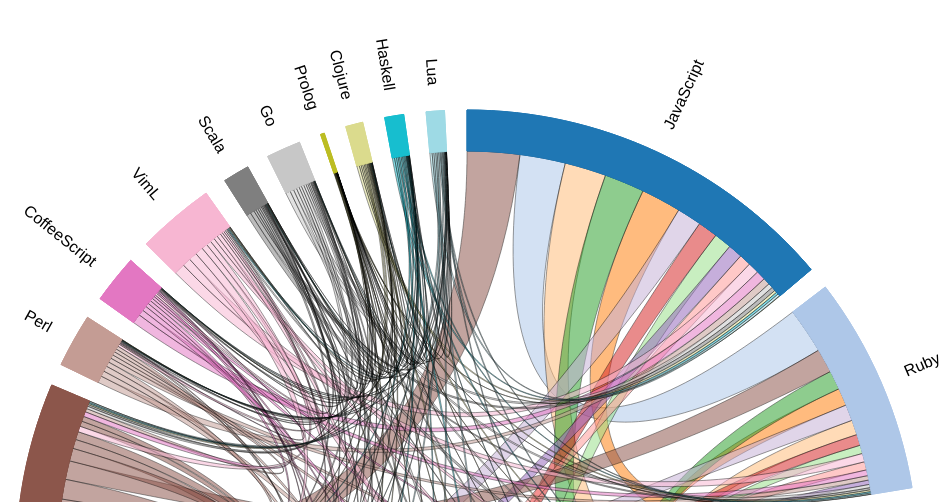
Well, now it’s 2021. The slide information needs to be updated, and Mr. van der Ende has not updated his image, but he was kind enough to make available his source code and a handy README file which walks (loosely) through how to get the data.
Challenges then solved so far:
- getting access to BigQuery
- finding new sources of the data, since the dataset van der Ende references doesn’t seem to exist anymore
- making BigQuery convinced that I have permission to run queries
- updating the query to match the new data source, including figuring out how to flatten arrays – really not in his original flow
- downloading mysql to my developer machine and setting up a database and username/password combo
- updating van der Ende’s code to read directly from a CSV, rather than assuming I’m using a JSON file
- getting php to work on my developer workstation – this particular box has done lots of things for me lately, but php hasn’t been one of them
- figuring out how to populate the languages list the code asked for, given the languages represented in the dataset I downloaded. (For the record, awk, sort, uniq was the happy combo.)
- uh, figuring out a better way to ingest the CSV, since pulling in the full file at once took up too much memory for my computer
- (more to come undoubtedly to get it working…)
Note: I ultimately ran into enough things with it that I left the original image. Still on my todo list to bring this to resolution…
Wireshark lessons learned
My masters classes keep sending us into Wireshark to analyze packet files. I thought I had a decent understanding of how to use Wireshark from some previous experience through work, but I keep finding new tricks as I try to figure out things about unknown protocols. Note that I’m using Wireshark 3.0.3, because that’s what’s installed in the lab infrastructure. I am aware that Wireshark 3.4 is out: my plan is to play with that version on my personal computer to see new goodies.
Copy and Paste
We keep needing to fill out spreadsheets of interesting things learned. We’re running Wireshark through a VDI infrastructure and I’m typically doing my homework on a laptop, so with limited screen real estate, even my touch typing skills aren’t helpful enough. The Copy capability in Wireshark lets me capture just the value for the field – highly useful for things like MAC addresses.
Protocol Hierarchy
Forget about randomly traversing files which including 100K packets – let the protocol hierarchy show likely interesting data points within the file. Filter by said protocol, and data patterns emerge. Worth calling out also the Conversations and Endpoints statistics areas, as well. Nice ways to get a holistic view of what’s going on in the file and what might be worth diving into.
Statistics -> …
We’re looking at SCADA pcap files, including BACnet. Delighted to find a traversal means for BACnet that let me inspect the devices and services seen in the pcap. I was less happy to see that iFix wasn’t in the list, and that Wireshark just treats it as plain TCP (again, with my older version of Wireshark, with its default set of dissectors, etc). Possibilities for expansion.
Expert Analysis
There’s a menu option for ‘Expert Analysis’ that I hadn’t played with before. Add its data, and then allow it to create filters to show just that data – voila. Evidence of TCP retransmissions? Yes, please.
Blast it, I’m going to do it the interesting way…
My masters class had us writing Yara rules for our project lab. Given that I recently gave a talk at DataWorks MD that took a brief foray into describing the use of Yara rules for static malware analysis – well – I was prepared for and looking forward to this particular lab.
The challenging part of the lab: to help us understand how analysts decide which byte(s) to check for hex strings, the lab had use the Linux utility, hexeditor. As instructed, we were to
- sudo hexeditor
- use the keyboard’s arrows to navigate into a particular file
- press Ctl-W to invoke ‘search’
- use the arrows to navigate to the hex search option, as opposed to text search
- type in the appropriate hex string. Note: the hex string could be longer than the editor would show us in its entry window. With a long enough string, we were then working blind with typos
- if the hex string was found, jot down at what byte position so that we could later use that in our Yara rules
Bleah… Too many opportunities for typos. Too slow, as we needed to iterate across five files. _Really_ too slow when you consider we were doing this in a VM hosted on university infrastructure, using its GUI via NoMachine.
Improvement 1: sudo hexeditor filename at least got me into a particular file, and importantly, let my file history show me what files I had already interacted with.
I then looked for command-line options to target hexeditor with a search string. That would at least let me repeat previous commands and edit the filename or the hexstring. Unfortunately, hexeditor doesn’t support anything of that sort. grep would apparently have gotten me to whether the pattern existed in the file, but not given me the byte location.
Long-ish story short, although the lab itself had no reason to cause me to do this, and it certainly took me longer to work this out than to just hand jam it, I now have scripts to iterate over a set of files and a set of hex strings to determine if the hex string is represented in the files, and if so, where. My geek demon is satisfied this evening, and I’m holding onto the files here to help in CTFs or other future geekish fun. Credit to here for the general approach for finding hex data locations in files, and here for helping work out the problem of iterating over lines that contain spaces.
#!/bin/bash
# test_hex_find.sh
# Examine file for hex value
# Argument 1: file name to check
# Argument 2: hex string to look for
position=$(od -v -t x1 $1 | sed 's/[^ ]* * //' | tr '\012' ' ' | grep -b -i -o "$2" | sed 's/:.*//')
if [ ! -z "$position" ]
then
position=$(( position/3 ))
echo "filename: $1, hex value: $2"
printf '%06X\n' $position
fi#!/bin/bash
# find_hex.sh
IFS=$'\n' hex_strings=( $(xargs -n1 <hex_strings.txt) )
for hex_string in ${hex_strings[@]}; do
echo $hex_string
done
for file in *.exe; do
for hex_string in ${hex_strings[@]}; do
./test_hex_find.sh $file "$hex_string"
done
done"C6 45 F4 74 C6 45 F5 6C C6 45 F6 76 C6 45 F7 63 C6 45 F8 2E C6 45 F9 6E C6 45 FA 6C C6 45 FB 73"
"8A 04 17 8B FB 34 A7 46 88 02 83 C9 FF"
"5C EC AB AE 81 3C C9 BC D5 A5 42 F4 54 91 04 28 34 34 79 80 6F 71 D5 52 1E 2A 0D"Things I’m reading
Things I’m in the middle of reading, also known as glimpses into my psyche:
- Thinking, Fast and Slow, by Daniel Kahneman: we’re reading this for our Women In Technology Group at work. So far, a couple of chapters in, my System 1 brain is convinced the book should progress more quickly
- The Clown in You, by Caroline Dream: reading this to try to think about my clowning in new ways, to spark my thinking in new paths
- Hacking, the Art of Exploitation, by Jon Erickson: my cyber masters program is leaving me less than inspired, and more feeling slogged in its various papers. Hoping this book gives me some new angles and inspiration
Did a thing…
Spent some time, did a thing, seemed to go over well.
Christmas domesticity
I’m more geek goddess than domestic diva. That said, tonight’s dinner was GOOD! Crab dip with pita chips, chicken and sausage jambalaya, and cheesy shrimp and grits. Oh, and I have dough rising for an attempt at beignets. The things you can do with a four day weekend… I had a day to shop and prep and have two days (!!) to recover.
I love having a happy family around the dinner table. We’re all in our pajamas – some of us in the Christmas family pajamas we put on last night, and some have changed into sets they got as Christmas presents. Our bellies are full and my heart is very happy.
Geek goofiness
Yeah, this kind of joke is just my kind. Thank you, Ian Coldwater, for enlivening my day. Thinking about posting it at work, too.
“YAML sounds like a root vegetable. Or a tuber.”
— Ian Coldwater ☸️🔥✨ (@IanColdwater) December 9, 2020
“Like a tubernetes? Running as root?”
“MOM!”
As the leader of our Women In Tech group for work, I particularly appreciate the pun-blaming on MOM! All the better that it’s the capitalized, exclamation-pointed version.